
SEO担当者、特に「ソースコード」を管理したり、編集する可能性がある方は絶対しっておきたいSEO用語の一つ、それが「robots.txt」です。
ただ、「横文字だしなんだか難しそう、自分に理解できるかな」と不安に思う方もいると思います。そこでこの記事ではrobots.txtに関する基礎知識から「具体的な活用方法」までわかりやすく解説します。
robots.txtとは
robots.txtとは、googleやyahooなどの「検索エンジン」にクロールして欲しくないページを管理するためのテキストファイルのことです。ファイル名は「robots.txt」で作成します。
テキストファイル(.txt)は、中身が文字(テキスト)だけのファイルという理解で問題ありません。
この「robots.txt」を活用することで「クロールしてほしいページ」と「クロールしてほしくないページ」を分けて管理することが可能になります。
robots.txtは何のために必要?
robots.txtは、自社サイトのページを「効率良くクロールしてもらうため」に必要です。
ページ数やファイル数が少ないサイトではrobots.txtを使わなくとも全てのページがクロールされる可能性もあります。
しかし、サイト内ページ数が数千〜数万規模の大規模サイトの場合は、クロール効率を上げるためにrobots.txtを使って「クロールさせるページ」と「クロールさせないページ」に分ける必要があるのです。
robots.txtを使うことで効率的に「評価させたいページ」をクロールしてもらうことができ、SEO観点からもプラスの効果が得られるようになります。
noindexとの違いは?
robots.txtと似た効果を持っている「noindex」というmetaタグがあります。noindexは、設定したページの「インデックス登録」をブロックする役割を持つmetaタグです。
この2つの主な違いは、以下の通り。
| robots.txt | noindex | |
| 効果 | クローラーの巡回を拒否する | 検索結果への登録を拒否する |
| 使用箇所 | txtファイルを作成する | HTMLのhead内に記述 |
robots.txtでクロールをブロックしてもインデックスされることはありますが、noindexを設定した場合はインデックスされることはありません。
そのため、検索結果に絶対表示させたくないページがある場合は、robots.txtで制御するのではなく、noindexをかけておく必要があります。
関連記事:noindexとは?
robots.txtはどのようなSEO効果がある?
robots.txtを適切に使ってあげることで、「重要度の高いページ」へのクロール頻度を高めることができます。クロール頻度が高くなれば、
- リライト
- 数値・データ更新
- 内部リンクの追加
などの変更を加えた際、検索エンジンに認知されやすくなります。そうすれば管理が行き届いているサイトとして、SEO評価を高められる可能性が高まるという仕組みです。
逆に、robots.txtを活用せず全ページにクローラーボットが巡回するようにしてしまうと、不必要な自動生成ページや重複コンテンツの中身を確認されてしまい、サイト評価を落とす原因にもなりかねないので注意しましょう。
robots.txtの使い方は?ケースごとに紹介
では具体的にrobots.txtはどんなケースで使うべきなのでしょうか。ここからは、robots.txtの実践的な知識について解説していきます。
紹介するケースは以下の3つ。
- 重要なページのクロール頻度を上げたいとき
- ページ数が膨大でbotがクロールしきるのが困難なとき
- ページ単位ではなくディレクトリ単位でクローラーをブロックしたい時
特にページ数が膨大な大規模サイトでしっかりrobots.txtを活用できていない場合には、しっかりと活用ケースを理解してサイト評価アップを狙っていきましょう。
重要なページのクロール頻度を上げたい時
SEO対策の一環として、サイト内の重要なページを効率よくクロールさせたい場合、robots.txtを適切に使ってあげることでクロールの効率を高めることができます。
まずは、サイト内コンテンツを「評価させたいページ」と「評価させないページ」の2つに仕分けします。そして後者のページ群をrobots.txtに記述することで、「評価させたいページのみにクローラーを巡回させられる」ということです。
しかし、ページ数の少ない小規模サイトの場合は、robots.txtを設定しなくても十分クローラーが巡回してくれるため高いSEO効果が得られない場合があることも覚えておきましょう。
とはいえ、今はページ数が少なくとも今後増えてくる可能性もあります。そして、増えてからページの仕分けをするとなると工数がかなり膨らんでしまいます。
そうならないためにも、今この記事を読み終わったタイミングからrobots.txtでクロールして欲しくないページの洗い出しは済ませるようにしましょう。
ページ数が膨大でクロールが困難なサイト
ページ数が何千〜何万単位の大規模サイトでは、robot.txtでクロール範囲を設定しないと評価してほしいページがうまく評価されなくなってしまう恐れがあります。
特に大規模サイトでは、
- エラーページ(404ページなど)
- カテゴリーページ
- ログインページ
- 画像・動画を格納してあるファイル
- ページ内切り替えで自動生成されるページ
- 過去に作成したコンテンツ量が極端に少ないページ
などクロールが不要なページが存在します。こうした不要ページをそのままにしておくと、クロール効率が下がるだけでなく、低品質コンテンツとして認識されかねません。
だからこそ不要ページにrobost.txtを設定することが重要でありSEO的にも有効なのです。
ページ単位ではなくディレクトリ単位でクローラーをブロックしたい時
robots.txtは特定のページだけではなく、ディレクトリ単位でクロールを制御することができます。
ディレクトリとはファイルを入れておく「箱」のようなもので、特定のディレクトリに入っているすべてのコンテンツをクロールして欲しくない場合に使えます。
サイトの運営方針が変わり、もう評価を狙っていないカテゴリーなどがある場合には、ディレクトリごとroboots.txtで制御するのが効率的です。
robots.txtを使うときの注意点
クローラーの制御をまとめてできる便利なテキストファイル、robots.txtですが使う際の注意点もいくつかあります。
robots.txtに限った話ではありませんが、SEO施策は正しく行わないと「悪影響」を及ぼしてしまう可能性があります。
ですから、しっかりと使用する上での注意点は必ず覚えるようにしましょう。
noindexとの併用は特に注意が必要
robots.txtと似た効果があるnoindexですが、この2つを併用する際には注意が必要です。正確には「併用」することは基本的におすすめしません。
具体的なケースを交えながらその理由を解説します。
具体例:
例えば、公開された記事がインデックス登録されたが、インデックスから削除したいとします。
その時にrobots.txtとnoindexを併用してしまうと、クローラーをブロックしてしまうためnoindexが設定さあれているかどうかクローラーは判断できません。
その結果、いつまでもインデックスから削除されない状態になってしまいます。
インデックスされたページを削除したい場合は、robots.txtが設定されていない状態にしてからnoindexをかける必要があるということです。
インデックスを拒否する目的で使わない
robots.txtは検索エンジンのクロールを拒否する仕組みであって、インデックスを拒否する仕組みではありません。
そのため、robots.txtでクロールをブロックしても他のサイトからリンクを受けた場合、ページがインデックスされる場合もあります。
ですから、確実にインデックスされるのを防ぐためにはnoindexを設定する必要があることも覚えておきましょう。
特にサイト内に重複コンテンツがあり、インデックスさせたくないページをrobots.txtに記述するやり方はNG。重複コンテンツ対策にはrobots.txtを使うべきではありません。
robots.txtで指定してもユーザーは閲覧できる
robots.txtはクローラーの巡回を制御するための設定のため、ユーザーの閲覧を制限することはできません。
ユーザーの目に触れて欲しくないコンテンツに関してはページを削除するか、該当ページへの導線を取り除いたうえで「noindex」をかけるようにしましょう。
もしくは、Wordpressを使用している場合なら「非公開設定」もできるので活用してみましょう。
反映まで時間がかかる
robots.txtは設定した瞬間に即時反映されるわけではありません。
Googleは24時間おきにrobots.txtの内容を更新しているため、大体1日以上反映に時間がかかってしまいます。
少しでも早くrobots.txtの設定を反映させたい場合は、Google Search Consoleを使って「robots.txtを更新したこと」を通知するようにしましょう。
robots.txtの書き方は?
続いて、robots.txtの具体的な書き方を説明していきます。「専門的なコードの知識が必要なのでは?」と不安に思うかもしれませんが、そんなことはありません。
誰でもrobots.txtが正しく書けるようにわかりやすく解説します。今回は、Google検索セントラル内で公開されているサンプルコードを見ながら、それぞれのテキストがどんな役割を担っているのか確認していきましょう。
まず、robots.txtは以下4つの要素で構成されています。
- User-agent
- Disallow
- Allow
- Sitemap
まずは各項目がどんな役割を担っているのか確認していきましょう。
User-Agent
User-Agentは制御するクローラーを指定する項目です。
基本的には全てのクローラーをブロックする「*(アスタリスク)」を設定しますが、Googleのみ、Yahooのみなど特定のクローラーだけをブロックしたい場合は「ブロックしたいクローラーの名前」を記述する必要があります。
例:Googleのクローラーをブロックする場合
User-agent: Googlebot
例:yahooクローラーをブロックする場合
User-agent: slurp
例:bingクローラーをブロックする場合
User-agent: BingBot
Disallow
Disallowはクロールをブロックしたいディレクトリやページを指定する項目です。「Dis(否定)+Allow(許可)=クロールを許可しない」と覚えましょう。
例えば以下のように記述した場合は、sampleというディレクトリの配下にあるコンテンツへのクロールをブロックできます。
Disallow: /sample/
特定のページへのクロールを拒否したい場合には以下のように記述します。
Disallow: /sample/sample.html
また、Googleの場合、以下のように記述すれば特定のファイル形式へのクロールをブロックできますが、他の検索エンジンでは標準的な書き方ではないため、クロールさせたくないサイト要素を特定のディレクトリ配下に整理しておくなど工夫が必要です。
Disallow:/*.pdf$
Allow
Allowはその名の通り「クロールを許可するディレクトリやページを指定する項目」です。
Allowを指定しなくてもクロールはされるため、基本的には記載しなくても問題ありません。
しかし、Disallowでクロールをブロックしたディレクトリ配下の一部のページだけクロールさせたい場合には該当ページまたはフォルダを指定するようにしましょう。
記述例
Disallow:/sample/
Allow:/sample/sample-allow/
上記の場合は、sampleという名前のディレクトリ配下のクロールをブロックして、例外として/sample-allow/配下のみクロールを許可するという意味になります。
Sitemap
Sitemapは、クローラーにWebサイトの構造を伝えるための項目です。クローラーがサイトで迷子にならないように構造を教えてあげるための「地図」だと思ってください。
必須項目ではないので書かなくでも問題はありませんが、Sitemapがあった方が効率的にクローラーがサイトを巡回できるため設定しておくことを推奨します。
robots.txtの記述例
記述例
User-agent: Googlebot
Disallow: /nogooglebot/
Allow: /nogooglebot/sample.html
Sitemap: https://example.com/sitemap.xml
この場合、Googlebotから/nogooglebot/配下のディレクトリへのクロールをブロックし、例外として/nogooglebot/配下のsample.htmlのクロールは許可するという意味になります。
また、WordPressで構築しているサイトの場合、デフォルトのrobots.txtは以下のように設定されています。
WordPressのrobots.txt
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/wp-sitemap.xml
デフォルトの設定ではクロールの必要がないWordPressの管理画面ページがクロールされないように設定されています。
robots.txtの確認方法
記述方法が分かったとしても、初めてrobots.txtを作るとなると「本当にこの書き方でいいのかな。エラーになってないかな。」と不安に思ってしまいますよね。
でも安心してください。Google Search Consoleのrobots.txtテスターを使うことで、作成したrobots.txtが正しい形式になっているかを確認することができます。
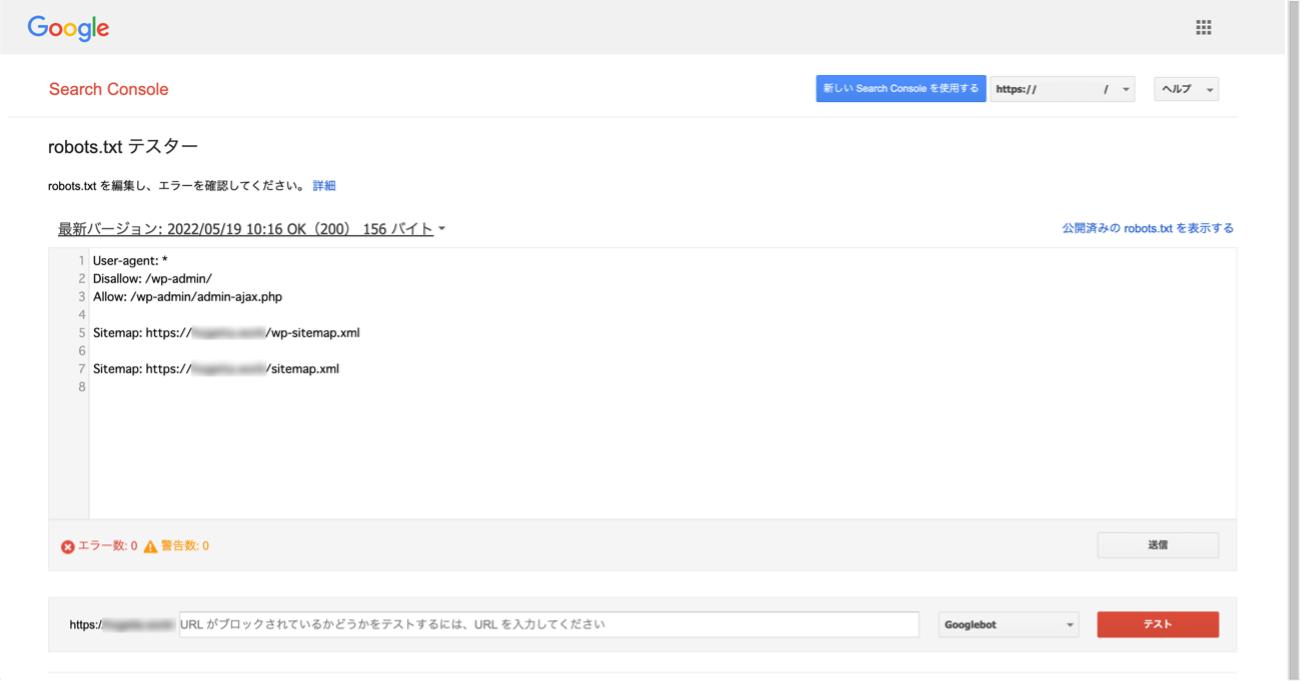
確認手順は以下の通りです。
- Google Search Consoleにアクセスし、確認したいrobots.txtの内容を貼り付ける。
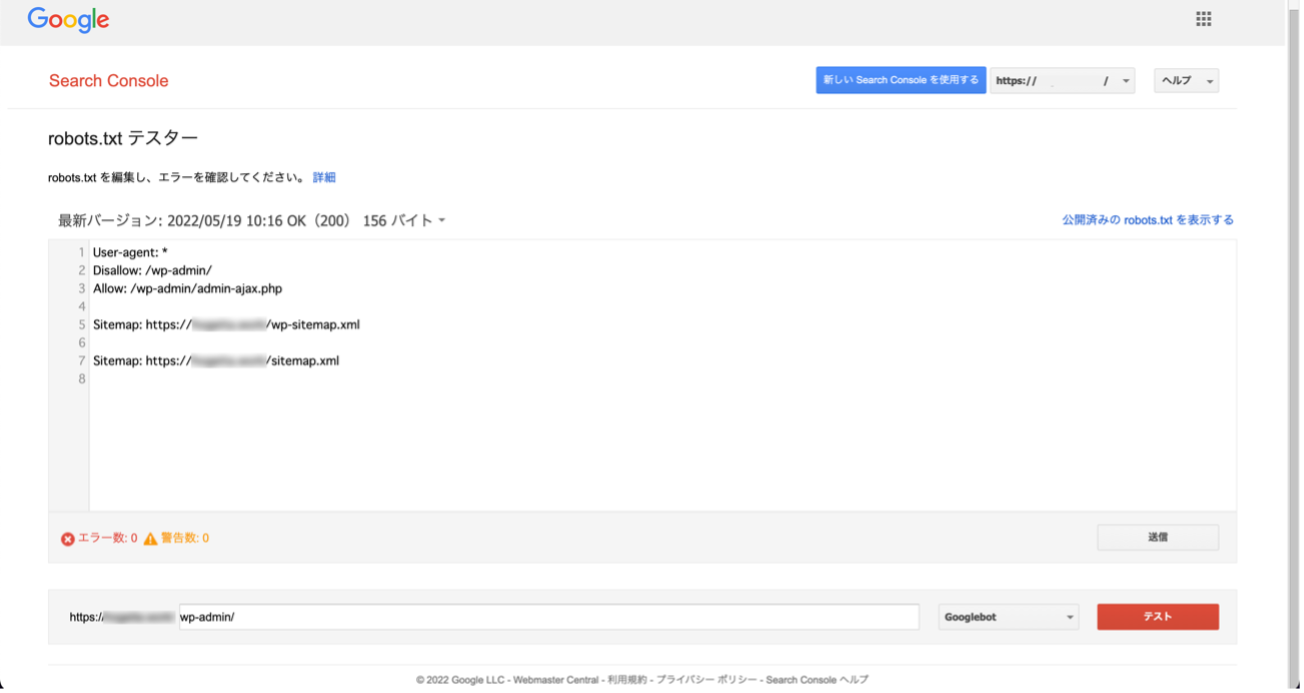
- 次にDisallowで指定したディレクトリやページがブロックされているかどうかを確認するために、下の枠にURLを入力する。
- 右側の赤いテストボタンを押下することテストを実行。
- 正しくrobots.txtでブロックできていれば、Disallowで記述した部分が赤く表示されます。
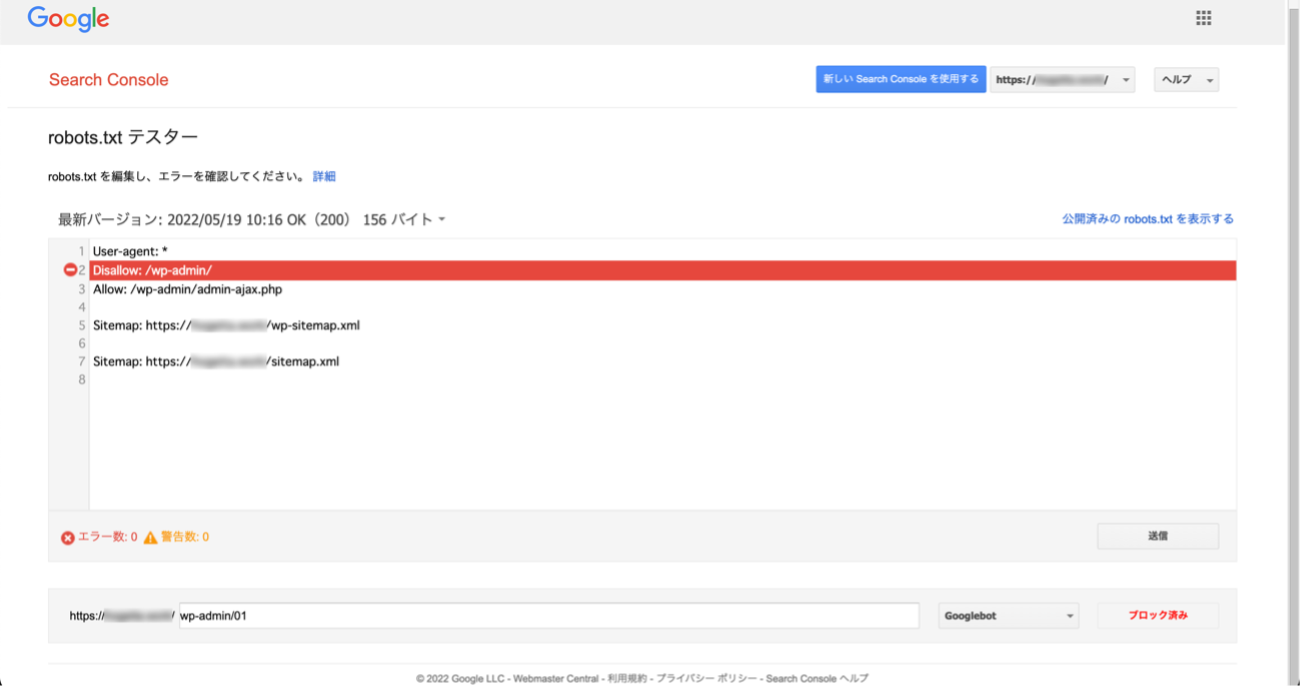
robots.txtの記述ミスはSEO観点でもマイナスになってしまうため、必ずテストをしてから設定させることをおすすめします。
robots.txtの設定方法
テストをしてrobots.txtの記述内容に問題がなかった場合は、FTPソフトを使ってrobots.txtをアップロードしましょう。
FTPソフトとは、「ファイルのアップロード/ダウンロード」を行うためのソフトのこと。FFFTPやFilesillaが有名ですね。
また、robots.txtはルートドメイン(ディレクトリ)にアップロードしなければいけません。ルートドメイン(ディレクトリ)というのは、そのサイトの最上部のドメイン(ディレクトリ)のことです。
サイト全体にrotbots.txtの内容を反映させるために、サイトの根っこ(root)であるディレクトリにアップロードすると覚えておきましょう。
まとめ
今回は、SEO施策にかかせない「robots.txt」について解説しました。
robots.txtなどを使ったSEO施策は一見地味ですが、効果はあなどれません。クローラー効率を最適化させるためにも、robots.txtをうまく活用して自分のサイト評価UPを目指しましょう。